GPT Detections on Windows and Linux
Introduction
This is a follow up to A Little Less Malware, applying the same techniques to Linux and Windows data. There are some differences with this experiment. In the last one, we used Apple’s ESF to collect telemetry, which gave us process group identifiers to work with. In this experiment, I’m using only the Elastic Agent and the process telemetry it provides. Unfortunately, Elastic Agent does not send PGID for Linux, and while Windows notionally supports the concept, in practice it does not exist. First let’s look at a couple of ways to group activity without PGIDs.
Grouping process activity
Sibling grouping
One method we can use is to group processes that share a common parent. In some cases this will get us a lot of context. Consider the children of rundll32.exe in the following image: 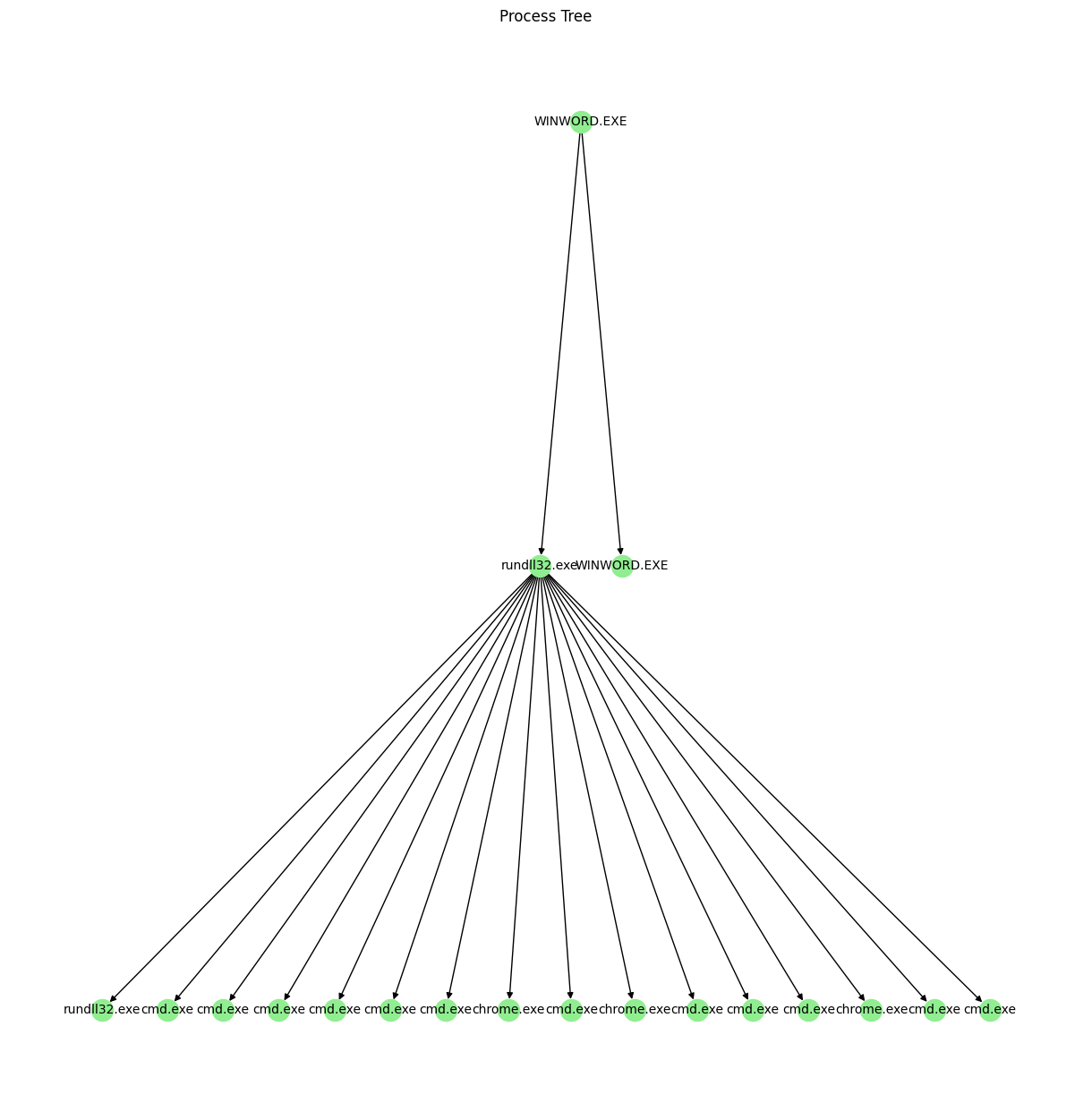 Almost each of those processes is an invocation of
Almost each of those processes is an invocation of shell from a Cobalt Strike Beacon. In a case like this, we’ll have very good context on what the attacker was doing. There are a few MITRE ATT&CK TTPs we would be able to see from looking at the siblings based on what each cmd.exe does - I have a mix of system discovery, credential access, and persistence. But one of the things we miss is some of the initial access/execution, hinted at by WINWORD.exe.
Grandparent grouping
Another method is to group by the grandparent PID where it exists and fallback to siblings if it doesn’t exist. Sometimes the grandparent PID will not be our Elastic query parameters. For example, if the grandparent process was Explorer and the computer has been and logged into for more than 24 hours, we would need to query a longer timespan to have the Explorer.exe execution log.
In the image above, this type of grouping will include WINWORD.exe, giving additional context to the LLM when assessing whether the commands are malicious.
Other groupings
I also tried a “largest lineage” that would use the Elastic Agent process.Ext.ancestry field. In this grouping, I searched all processes on a host to find the oldest ancestry. Then for each of those ancestor entity IDs, I searched back down to gather all their descendants, effectively creating a large number of “branches” of the process tree. While this method gave a ton of context due to the amount of process data in each grouping, I found it unwieldy in detections because so many cousin processes would get caught in the detection.
In this initial test, grandparent grouping performed better.
Assessing performance
Unlike in the last blog, I’m not going to root cause each false positive and false negative because the data I used for this experiment is the same data I use for a midterm. I will show the confusion matrices and provide some high level observations. I will also work on “anonymizing” the data so that it can be shared.
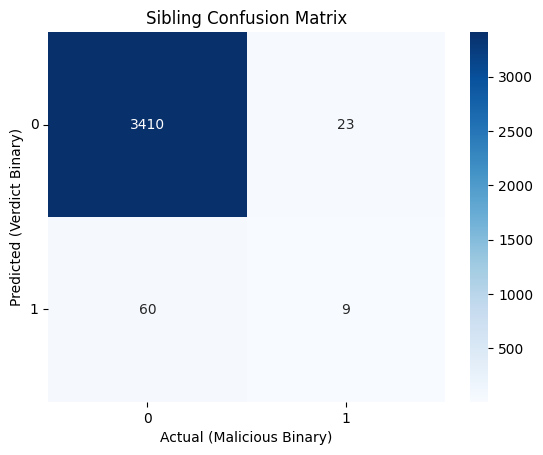 The sibling grouping method had a true positive rate of 28% which is not great. A lot of the false negatives come from processes at the end of a chain. Thinking back to the process tree picture above, what’s not shown is that the cmd.exe are the parent process of another command, such as systeminfo. If the full sequence of commands looks like the following:
The sibling grouping method had a true positive rate of 28% which is not great. A lot of the false negatives come from processes at the end of a chain. Thinking back to the process tree picture above, what’s not shown is that the cmd.exe are the parent process of another command, such as systeminfo. If the full sequence of commands looks like the following:
1
2
3
4
5
6
winword.exe (PID 1000)
└── rundll32.exe (PID 2000)
├── cmd.exe (PID 3000)
│ └── systeminfo (PID 4000)
└── cmd.exe (PID 3001)
└── icacls (PID 4001)
In the whole we could recognize a pattern of system discovery, finding a weakly permissions service binary, and then replacing it. Our full command line would look like C:\windows\system32\cmd.exe /c systeminfo. When we have the full command line and we group by sibling, the rundll32.exe grouping will correctly be found malicious. However, because we also group the cmd.exe processes individually, we get a group that has just systeminfo or just icacls, which is not enough for the LLM to correctly assess. 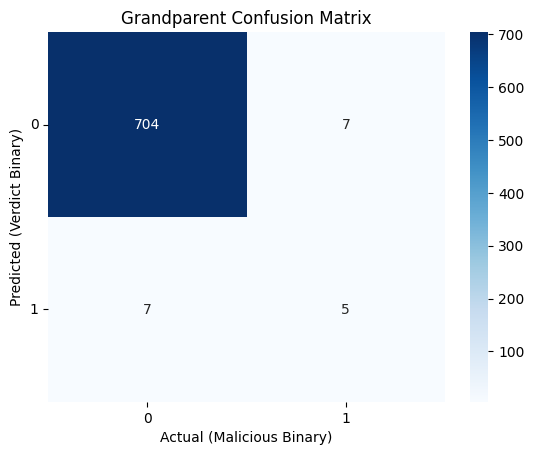 The grandparent grouping method had a true positive rate of 42%. While that is significantly better than the sibling grouping, it’s still worse than a coin toss.
The grandparent grouping method had a true positive rate of 42%. While that is significantly better than the sibling grouping, it’s still worse than a coin toss.
Of the seven false negatives, five were on a Linux machine. The first three were assessed as not suspicious because of how I grouped commands. I labeled a whole SSH session as malicious and this mostly worked, except when some grandchildren of the sshd process had their own grandchildren. A more judicious labeling of the individual SSH session commands would have improved the scoring here.
The two false negatives from the Windows machine were part of the user simulator. These processes were in the chain of processes that led to Cobalt Strike running. Similar to the Linux processes, they are “collateral damage” of how I labeled and then grouped processes as malicious.
There were also seven false positives, which all came from a Windows machine. I had a scheduled task running every 15 minutes. GPT seemed to have gotten confused on the repetitive nature of these tasks. This accounted for two of the false positives. Four false positives came from Cloudbase-Init scripts. The last false positive was from the user simulator.
While the false negatives are mostly easy to fix (label data more rigorously), the false positives are harder to fix. On the one hand, a detections team could suppress alerts from specific commands - for example, Cloudbase-Init. But on the other hand, it would be nice to not have to take traditional detection engineering approaches when using AI. Another method to overcome this could be with retrieval. Instead of a detection engineer needing to suppress alerts for specific processes, we could feed additional context into the LLM assessment, such as software inventory or configuration management output.
I have a few things more to try in AI detections and hopefully will find the time to do them soon!